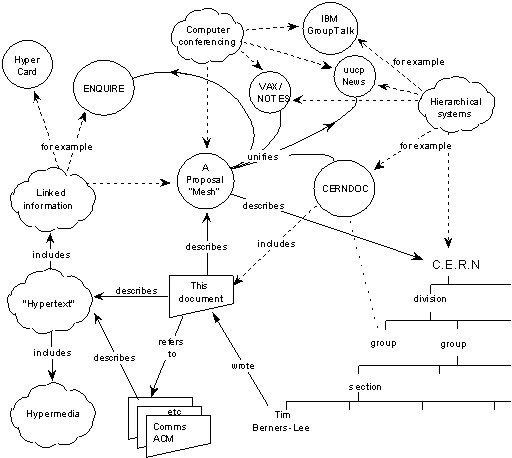
 Yesterday I attended "World Wide Web@20" at CERN in Geneva where Web founders celebrated the 20 years of the "Original proposal for a global hypertext project at CERN" (1989). Tim Berners-Lee, Ben Segal, Jean-Francois Groff, Robert Cailliau and others gave a set of talks about the history and the future of the Web.
Yesterday I attended "World Wide Web@20" at CERN in Geneva where Web founders celebrated the 20 years of the "Original proposal for a global hypertext project at CERN" (1989). Tim Berners-Lee, Ben Segal, Jean-Francois Groff, Robert Cailliau and others gave a set of talks about the history and the future of the Web.
The afternoon was quite dense inside the CERN globe and I won't summarize every talks. I only wanted to write down the set of insights I collected there.
First about the history:
- The main point of Berners-Lee was that "people just need to agree on a few simple things", which was quite a challenged in the context of emergence of his invention: CERN. At the time, computers and IT in general was a zoo. There were many companies(OS), network standards were different (each company had at least one, CERN had its own... TCP/IP just began to appear form the research environment but were opposed by European PTTs and industry).
- What was interesting in the presentation was the context of CERN itself: computing was really one of the last important thing in terms of political order (after physics and accelerators). Desktops, clusters and networking were also perceived as less important as big mainframes. And of course, TCP/IP was considered "special" and illegal until 1989! To some extent, there was an intriguing paradox: the Web was created at CERN but from its weakest part and using "underground" resources
- The Web wasn't understood at first. This paradigm shift was not understood, people did not get why they should put their data on this new database because they did not understand what it would lead to The key invention was the url, something you can write on a piece of paper and give to people
- Berners-Lee also pointed out the importance of the Lake Geneva area ("looking at the Mont Blanc this morning I realized how much you take it for granted when you live here") and how the environment was fruitful and important in terms of diversity (researchers coming from all around the World).
- The basic set of things people should agree on was quite simple:
- URIs
- HTML was used for linking but it ended up being the documentation language of choice
- Universality was the rule and it worked, an important step was having CERN not charging royalties
- It was also interesting to see how the innovation per se was more about integrating ideas and technologies than starting something from scratch. As shown during the demo of the first webserver and by the comments on the first research papers about the Web, it was all a matter of hyperlinks, using an existing infrastructure (the internet), URI and of course the absence of royalties from CERN. People just needed to agree on a few simple things as TBL repeated.
The future part was very targeted at W3C thinking about the web future. As Berners-Lee mentioned "the Web is just the tip of the iceberg, new changes are gonna rock the boat even more, there are all kinds of things we've never imagined, we still have an agenda (as the W3C)". The first point he mentioned was the importance for governments and public bodies to release public data on the web and let people have common initiative such as collaborative data (a la open street map). His second point here was about the complexity of the Web today:
"the web is now different from back then, it's very large and complicated, big scale free system that emerged. You need a psychologist to know why people make links, there are different motivations we need people who can study the use of the web. We call it Web Science, it's not just science and engineering, the goal is to understand the web and the role of web engineering"

And eventually, the last part was about the Semantic Web, the main direction Tim Berners-Lee (he and the team of colleagues he invited in a panel) wanted to focus on for the end of the afternoon. From a foresight researchers standpoint, it was quite intriguing to see that the discussion about the future of the Web was, above all, about this direction. Berners-Lee repeated that the Semantic Web will happen eventually: "when you put an exponential graph on an axis, it can continue during a lot of time, depending on the scale... you never know the tipping point but it will happen". The "Web of data" as they called it was in the plan from the start ("if you want to understand what will happen, go read the first documents, it's not mystical tracks, it's full of clever ideas"): we now have the link between documents and the link between documents and people or between people themselves is currently addressed. Following this, a series of presentation about different initiatives dealt with:
- grassroots effort to extent the web with data commons by publishing open license datasets as linked data
- the upcoming webpresence of specific items (BBC programs)
- machine-readable webpages about document
- machine-readable data about ourselves as what Google (social graph API), Yahoo, Russia (yandex) are doing: putting big database of these stuff once you have this, you can ask questions you did not have previously. FOAF is an attempt into this direction too.
The last part of the day was about the threats and limits:
- Threats are more at the infrastructure level (net neutrality)than the Web level, governments and institution which want to snoop, intercept the web traffic
- A challenge is to lower the barrier to develop, deploy and access services for those devices, which should also be accessible for low literacy rates, in local languages (most of which are not on the web).
- One of the aim is to help people finding content and services even in developing countries. It's also a way to empower people.
- The dreamed endpoint would be the "move form a search engine to an answer engine : not docs but answers" and definitely not a Web "to fly through data in 3D".
Why do I blog this? The whole afternoon was quite refreshing as it's always curious to see a bunch of old friends explaining and arguing about the history of what they created. It somewhat reminded me how the beginning of the Web as really shaped by:
- a certain vision of collaboration (facilitating content sharing between researchers), which can be traced back to Vannevar Bush's Memex, Ted Nelson's Xanadu, the promises of the Arpanet/Internet in the 70s (Licklider).
- the importance of openness: one can compare the difference between the Web's evolution and other systems (Nelson's work or Gopher). What would have happened if we had a Gopher Web?
- a bunch of people interested in applying existing mechanisms such as hypertext, document formating techniques (mark up languages)
What is perhaps even more intriguing was that I felt to what extent how their vision of the future was still grounded and shaped by their early vision and by their aims. Their objective, as twenty years ago, is still to "help people finding content, documents and services", the early utopia of Memex/Arpanet/Internet/Xanadu/the Web. The fact that most of the discussion revolved around the Semantic Web indicates how much of these three elements had an important weight for the future. Or, how the past frames the discussants' vision of the future.
Curiously enough the discussion did not deal with the OTHER paths and usage the Web has taken. Of course they talked briefly about Web2.0 because this meme is a new instantiation of their early vision but they did not comment on other issues. An interesting symptom of this was their difficulty in going beyond the "access paradigm" as if the important thing was to allow "access", "answers" and linkage between documents (or people). This is not necessarily a critique, it's just that I was impressed by how their original ideas were so persistent that they still shape their vision of the future.