The "Parking Wars" application on Facebook was certainly one my favorite game two years ago. I gave it a shot for 3-4 months and then let it go (although one my friend is a "$28,699,245 (Parker Emeritus)". Besides it may have been the only application that attracted me to log in on Facebook back in 2006.
The "Parking Wars" application on Facebook was certainly one my favorite game two years ago. I gave it a shot for 3-4 months and then let it go (although one my friend is a "$28,699,245 (Parker Emeritus)". Besides it may have been the only application that attracted me to log in on Facebook back in 2006.
The game, designed by Area/Code was actually a facebook app that was meant to promote a television show:
" In Parking Wars, players earn money by parking -- legally or illegally -- on their friend's streets. Players also collect fines by ticketing illegally parked cars on their own street."
What was fantastic at the time was the fact that this simple games app took advantage of the FB social graphs in curious ways:
- The underlying logic is simple: you need to have friends to park your cars on their street. The point is therefore to maximize the number of friends who play Parking War... which leads player to participate in the network effect through invitations (on top of word-of-mouth).
- The game is asynchronous and turn-based so it's good to find friends on different time-shift so that you could place/remove your car when they sleep (a moment during which you don't risk to get any fine).
- When giving a fine you can send messages to other players, the dynamic here is highly interesting as people repurposed it into some weird communication channel that is public but that address a different audience than the Facebook wall
- Competition is stimulated with a peculiar kind of score board: you only see scores from other players within your network (who added the game). This is thus a sort of micro-community where each participants' score is made explicit.
- The "level design" is also interesting with a "neighbor" feature that enable you to park on adjacent streets, which can be owned by people outside your network.
- The cheating tricks are also social: you can less-active FB users to add the game so that you're pretty sure they won't check that you're illegally parked, you can create a fake FB account or benefit from streets created by people who stopped playing.
- ... and I am sure there is more to it from the social POV
Interestingly, my curiosity towards Parking Wars came back up to the surface when chatting with my neighbor Basile Zimmermann who works as research scientist at the University of Geneva. In a recent project, he addressed how Chinese Social Networking Sites re-interpreted design concepts already used by existing platforms such as FB and turned them into something different.
Which is how he showed me a curious application he saw on a Chinese SNS called "开心网 / Kaixin001" ("Happy Network") that is a Parking Wars-inspired copy also called "争车位" ("Parking Wars") which appeared in July 2008:

The layout is similar to the one created by Area/code, some cars are more fancy than others but the main difference lies in the presence of advertisement (as shown by the "LG" brand). As a matter of fact, the ad part was not included in the first few months of this Parking Wars version on the Happy Network and it appeared approximately around March 2009 according to Basile. From what I'm told, the game is evolving too with a system of maps that operates differently from the FB version.
More explanation in his upcoming paper about this topic: Zimmermann, B. (forthcoming). "Analyzing Social Networking Web Sites: The Design of Happy Network in China" in Global Design History, Adamson, Teasley and Riello eds, Routledge.
Why do I blog this? dual interest here: 1) my fascination towards Parking Wars and its underlying game design mechanism based on social dimensions, 2) the transfer of this meme in another culture.

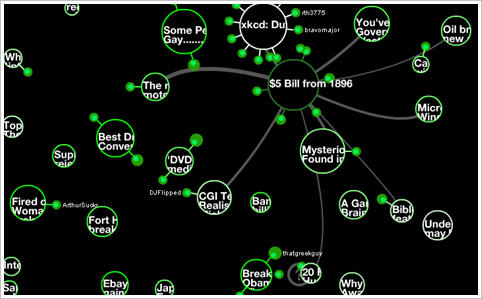 (Picture of Stamen's Digg swarm visualization)
(Picture of Stamen's Digg swarm visualization)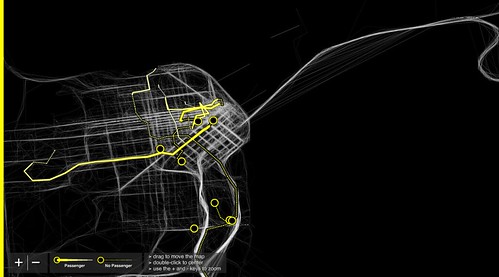 (Picture of Stamen's Cabspotting)
(Picture of Stamen's Cabspotting)